Ghaith Dkmak
A chronic learner, perseverant, trilingual data scientist with 5 years of experience in multiple fields such as data consulting, AdTech, research and humanitarian. For the time being, my focus lies in building production-ready NLP applications. My practical expertise in applying a wide range of inferential and predictive models allowed me to foster publishers' visitors-to-subscribers conversion rate, boost the user base for SaaS companies, and increase the time and effectiveness of aid delivery programmes.
In this page I present some of my work using Machine Learning, NLP, inferential analysis with different frameworks, libraries and languages such as python, TensorFlow, sklear, Flask and others.
View My LinkedIn Profile
Portfolio
NLP:
Turkish Sentiment Analysis GitHub
This project shows a comparison between three different approaches to train and test sentiment classification model to identify people’s opinions in Turkish language and label them as positive or negative, based on the emotions people’s express within them. Two Machine Learning techniques are namely Logistic Regression and Naive Bayes. Then Neural Networks using Embedding and 1D convolutional layers. Finally, the state-of-the-art pretrained BERT model is used to yield the best results. the following figures are yield from testing the models.
| Preprocessing | Naive Bayes | Logistic Regression | Deep Learning | BERT |
|---|---|---|---|---|
| No | 87% | 88% | 88% | 95% |
| Yes | 82% | 82% | 83% | 88% |
Technologies used: TensorFlow, Keras, sklearn, Transformer, Torch, Flask
ChatBot Lorenzo
![]() GitHub
GitHub
Lorenzo is a chatbot built using the awesomeness of Transformers library and Microsoft’s Large-scale Pretrained Response Generation Model (DialoGPT). Try to talk to Lorenzo he is still learning.
Analytics:
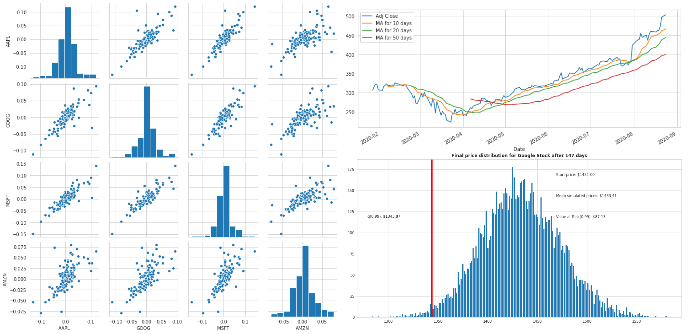
Stock Market Analysis For Apple, Google, Microsoft and Amazon GitHub
Stock market for the big four technology stocks, Apple, Microsoft, Amazon, and Google. Main goal here to visualise and take a deep look at different way to analyse the risk of stocks considering their history changes.
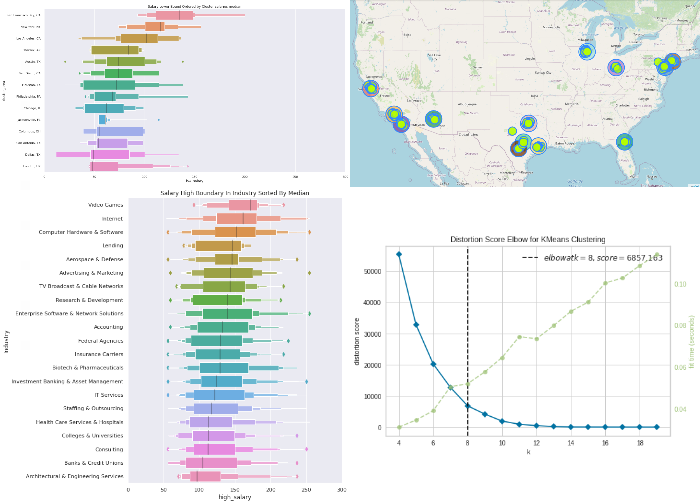
EDA Data Science Jobs Google Colab
In this anlysis explore Data Science Jobs during pandamic, and try to explore some hidden detailes in mutiple industries and for different job describtions. The dataset was created by picklesueat and contains more than 3900 job listing for data scientist positions scraped from glassdoor and other sites.
Hypothesis Testing And Predictive Analysis GitHub
The data is taken from lacity.org website. It has payroll information for all Los Angeles City Employees including the City’s three proprietary departments: Water and Power, Airports and Harbor. Two types of hypothesis testing is applied to check if there is a difference in the payroll between two years 2015 and 2016. In addition, predictive analysis is implemented using Random Forest and Linear Regression.
Computer Vision
Human_activity_correctness (Dissertation) GitHub
Evaluating Pre-processing Methods with Deep Learning Algorithms on Human Activity Skelton Data Obtained from Kinect and Vicon Sensors. The aim, here, is to investigate how to yield optimal results in this field by trying various different approaches at every stage of skeleton data processing; as a consequence of this work, HAR might take a significant step forward. This reposotry tries to tackle the issue of variable sized inputs using dataset called UI-PRMD.
The approach used is based on drawing New Joint coordinates on the Trajectory Based on a Threshold.
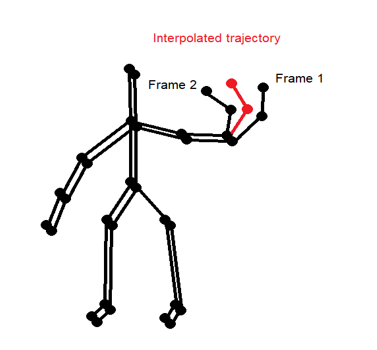
This figure shows two consecutive frames in elbow flexion gesture. The gap between the frames in the right arm space is relatively big and exceeded the threshold. Therefore, we filled this gap with a body coordinates and hence a frame.
Time Series
Cryptocurrency and Social Media (University project) GitHub
The project aim is to analyse influences of social media, in particular Twitter, on Bitcoin rate, in the current time period (Q1 2019). Therefore, we will apply different machine learning methods and algorithms to identify common trends and make forecasts as accurate as possible.